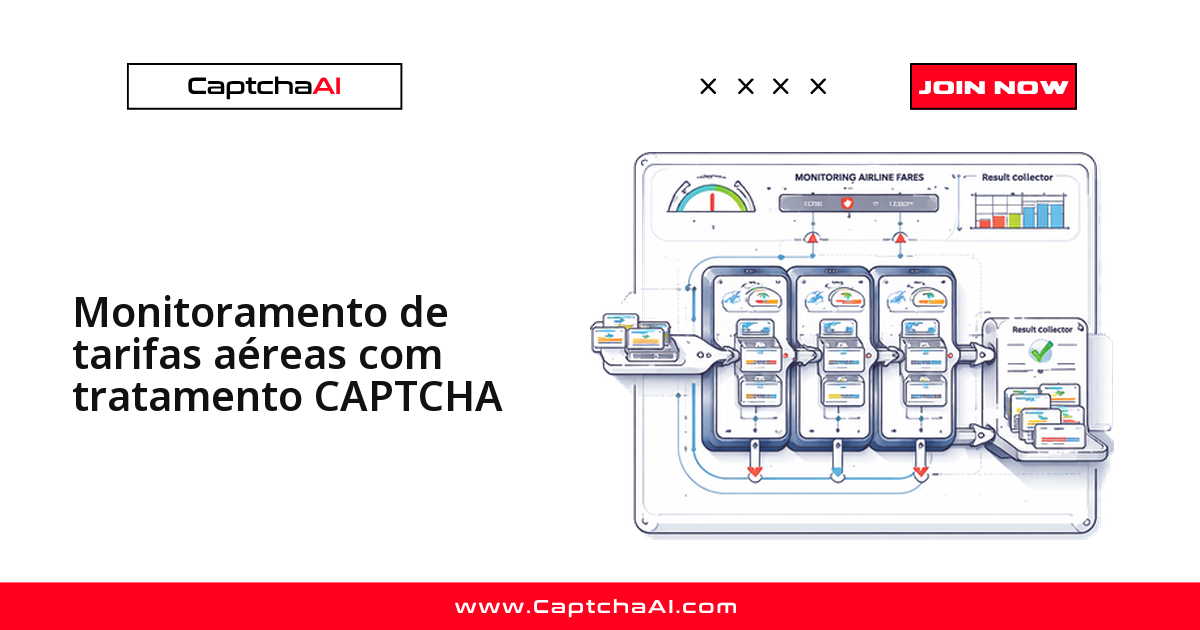
Seu script parou de trazer cotações do nada? Boa chance de ter esbarrado num reCAPTCHA v2 ou num Cloudflare Turnstile no meio do caminho: screeners de ações, o SEC EDGAR e a maioria dos provedores de dados de mercado ativam um desafio assim que percebem volume de requisições fora do padrão humano. Este guia mostra onde esses CAPTCHAs aparecem nas principais fontes financeiras e como resolvê-los em Python com a API da CaptchaAI, sem precisar reescrever o pipeline toda vez que um provedor muda a defesa.
Se o pipeline também grava histórico de cotações ou dados vinculados a investidores pessoa física, vale lembrar que a LGPD trata isso como dado pessoal quando associado a CPF ou conta — mantenha a coleta focada em dados públicos agregados e documente a finalidade do tratamento.
Onde o CAPTCHA aparece nas fontes de dados financeiros
A tabela abaixo resume os pontos mais comuns onde a coleta trava e o que costuma disparar o desafio:
| Fonte | Tipo de CAPTCHA | Gatilho | Valor do dado |
|---|---|---|---|
| SEC EDGAR | reCAPTCHA v2 | Volume alto de requisições | Arquivamentos da empresa |
| Yahoo Finance | reCAPTCHA v2 | Detecção de scraping | Cotações e histórico de preços |
| Bloomberg | Cloudflare Turnstile | Todo acesso automatizado | Dados de mercado |
| Finviz | reCAPTCHA v2 | Acesso ao stock screener | Resultados de triagem |
| TradingView | Cloudflare Challenge | Rate limit | Gráficos e indicadores |
| Morningstar | reCAPTCHA v3 | Páginas de exportação de dados | Análise de fundos |
Repare que Bloomberg e TradingView usam as duas variantes de proteção da Cloudflare — Turnstile e Challenge —, então o pipeline precisa tratar ambas, não só o reCAPTCHA.
Sinais de que sua coleta está sendo limitada
Antes de sair resolvendo CAPTCHA em tudo, vale confirmar que é isso mesmo que está travando o pipeline:
- Respostas 403 ou 429 que aumentam junto com o volume de requisições
- HTML de retorno trazendo
data-sitekeyou o script do Turnstile no lugar dos dados esperados - JSON válido nos primeiros minutos e, depois, só página de desafio
- A mesma consulta funciona no navegador comum e falha apenas no script
Como não estourar o rate limit dos provedores financeiros
Sites financeiros costumam ser mais rígidos com acesso automatizado do que o e-commerce médio — o gatilho para CAPTCHA aparece mais cedo:
| Prática | Recomendação |
|---|---|
| Intervalo entre requisições | 2 a 5 segundos entre páginas |
| Conexões simultâneas | Máximo de 3 a 5 por domínio |
| Tipo de egress | Residencial ou ISP dedicado |
| Duração da sessão | Sessões fixas de 5 a 10 minutos |
| User-Agent | Realista e consistente durante toda a sessão |
| SEC EDGAR | E-mail de contato no User-Agent (obrigatório) |
| Horário de mercado | Colete fora do horário de pico do pregão, quando possível |
Solução de problemas comuns
| Problema | Causa | Correção |
|---|---|---|
| 403 no SEC EDGAR | User-Agent sem e-mail de contato | Adicionar cabeçalho CompanyName email@domain |
| CAPTCHA em toda requisição | Rate limit excedido | Adicionar 3 a 5 segundos de intervalo entre requisições |
| Preço desatualizado no retorno | Resposta em cache | Adicionar parâmetro de consulta cache-bust |
| Erro ao fazer parse do JSON | Página de CAPTCHA retornada no lugar dos dados | Verificar se veio CAPTCHA antes de tentar o parse |
| IP bloqueado | Muitas requisições do mesmo IP | Trocar para egress de rede autorizado com rotação |
Coleta de dados de screener de ações em Python
O padrão abaixo detecta a sitekey na resposta, resolve o reCAPTCHA v2 via CaptchaAI e reenvia o token antes de extrair a tabela de resultados:
import requests
import time
from bs4 import BeautifulSoup
import re
CAPTCHAAI_KEY = "YOUR_API_KEY"
CAPTCHAAI_URL = "https://ocr.captchaai.com"
def solve_captcha(method, sitekey, pageurl, **kwargs):
data = {
"key": CAPTCHAAI_KEY,
"method": method,
"googlekey": sitekey,
"pageurl": pageurl,
"json": 1,
}
data.update(kwargs)
resp = requests.post(f"{CAPTCHAAI_URL}/in.php", data=data)
task_id = resp.json()["request"]
for _ in range(60):
time.sleep(5)
result = requests.get(f"{CAPTCHAAI_URL}/res.php", params={
"key": CAPTCHAAI_KEY, "action": "get",
"id": task_id, "json": 1,
})
r = result.json()
if r["request"] != "CAPCHA_NOT_READY":
return r["request"]
raise TimeoutError("Solve timeout")
class FinancialScraper:
def __init__(self, proxy=None):
self.session = requests.Session()
if proxy:
self.session.proxies = {"http": proxy, "https": proxy}
self.session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 Chrome/126.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
})
def scrape_screener(self, url):
"""Scrape stock screener, handling CAPTCHA if triggered."""
resp = self.session.get(url, timeout=30)
# Check for CAPTCHA
sitekey_match = re.search(r'data-sitekey="([^"]+)"', resp.text)
if sitekey_match:
sitekey = sitekey_match.group(1)
token = solve_captcha("userrecaptcha", sitekey, url)
# Resubmit with token
resp = self.session.post(url, data={
"g-recaptcha-response": token,
})
return self._parse_stocks(resp.text)
def _parse_stocks(self, html):
soup = BeautifulSoup(html, "html.parser")
stocks = []
for row in soup.select("table.screener-table tr")[1:]:
cols = row.select("td")
if len(cols) >= 8:
stocks.append({
"ticker": cols[1].get_text(strip=True),
"company": cols[2].get_text(strip=True),
"sector": cols[3].get_text(strip=True),
"price": cols[6].get_text(strip=True),
"change": cols[7].get_text(strip=True),
})
return stocks
# Usage
scraper = FinancialScraper(
proxy="http://user:pass@residential.proxy.com:5000"
)
stocks = scraper.scrape_screener("https://screener.example.com/screener.ashx?v=111")
for stock in stocks[:5]:
print(f"{stock['ticker']}: {stock['price']} ({stock['change']})")
A classe FinancialScraper guarda a sessão e o proxy configurado, então reutilize a mesma instância entre chamadas em vez de recriar a sessão a cada ticker — isso reduz o número de vezes que o site pede um novo desafio.
Extração de arquivamentos do SEC EDGAR sem bloqueio
O SEC EDGAR aplica rate limit e CAPTCHA agressivamente em acesso de alto volume, e exige um User-Agent identificável — sem isso, a maioria das requisições recebe 403 antes mesmo de chegar ao CAPTCHA:
import json
class SECFilingScraper:
BASE_URL = "https://efts.sec.gov/LATEST"
def __init__(self, user_agent_email, proxy=None):
self.session = requests.Session()
if proxy:
self.session.proxies = {"http": proxy, "https": proxy}
# SEC requires identifying User-Agent
self.session.headers.update({
"User-Agent": f"CompanyName admin@{user_agent_email}",
"Accept": "application/json",
})
def search_filings(self, company, filing_type="10-K"):
"""Search EDGAR for specific filing types."""
url = f"{self.BASE_URL}/search-index"
params = {
"q": company,
"dateRange": "custom",
"forms": filing_type,
}
resp = self.session.get(url, params=params, timeout=30)
# Handle CAPTCHA if triggered
if "captcha" in resp.text.lower() or resp.status_code == 403:
sitekey = self._extract_sitekey(resp.text)
if sitekey:
token = solve_captcha("userrecaptcha", sitekey, url)
resp = self.session.post(url, data={
**params,
"g-recaptcha-response": token,
})
return resp.json() if resp.status_code == 200 else {}
def download_filing(self, filing_url):
"""Download individual filing document."""
resp = self.session.get(filing_url, timeout=60)
if resp.status_code == 200:
return resp.text
return None
def _extract_sitekey(self, html):
match = re.search(r'data-sitekey="([^"]+)"', html)
return match.group(1) if match else None
# Usage
sec = SECFilingScraper(
user_agent_email="example.com",
proxy="http://user:pass@proxy.example.com:5000",
)
filings = sec.search_filings("Apple Inc", "10-K")
Resolvendo o Cloudflare Turnstile em provedores de dados de mercado
Bloomberg e outros provedores de nível institucional usam o Cloudflare Turnstile em vez do reCAPTCHA — o fluxo muda de token (cf-turnstile-response) mas a lógica de resolução via CaptchaAI é a mesma:
def scrape_turnstile_market_data(url, sitekey):
"""Handle Cloudflare Turnstile on financial data sites."""
token = solve_captcha("turnstile", sitekey, url)
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 Chrome/126.0.0.0 Safari/537.36",
})
resp = session.post(url, data={
"cf-turnstile-response": token,
}, timeout=30)
return resp.json() if resp.status_code == 200 else None
Use Turnstile em vez de reCAPTCHA quando:
- O provedor for Bloomberg ou outra plataforma de nível institucional
- A resposta trouxer um script
challenges.cloudflare.comno lugar dodata-sitekeydo Google - O erro 403 vier acompanhado de um cabeçalho
cf-mitigated
Automatizando a coleta diária de cotações
Para monitorar uma carteira de tickers todo dia sem intervenção manual, agende a função abaixo — ela reaproveita FinancialScraper e já grava o resultado em CSV:
import csv
from datetime import datetime
def daily_market_snapshot(tickers, output_dir="data"):
"""Collect daily stock data, handling CAPTCHAs automatically."""
scraper = FinancialScraper(
proxy="http://user:pass@residential.proxy.com:5000"
)
date_str = datetime.now().strftime("%Y-%m-%d")
results = []
for ticker in tickers:
url = f"https://screener.example.com/quote.ashx?t={ticker}"
try:
data = scraper.scrape_screener(url)
if data:
results.extend(data)
time.sleep(2) # Rate limit
except Exception as e:
print(f"Error on {ticker}: {e}")
# Save to CSV
filepath = f"{output_dir}/market_{date_str}.csv"
with open(filepath, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["ticker", "company", "sector", "price", "change"])
writer.writeheader()
writer.writerows(results)
print(f"Saved {len(results)} records to {filepath}")
return results
# Run daily
tickers = ["AAPL", "GOOGL", "MSFT", "AMZN", "TSLA"]
daily_market_snapshot(tickers)
Uma carteira pequena, consultada a cada minuto durante o pregão, roda tranquilamente num plano BASIC (US$ 15/mês, 5 threads). Para acompanhar centenas de tickers em paralelo ou combinar screener, SEC EDGAR e Turnstile ao mesmo tempo, o ADVANCE (US$ 90/mês, 50 threads) dá mais fôlego sem precisar reescrever a lógica de resolução.
Perguntas frequentes
Coletar dados financeiros públicos é legal no Brasil?
Sim, dentro de limites claros. Arquivamentos públicos e cotações de ações são geralmente permitidos — o próprio SEC EDGAR disponibiliza acesso explicitamente para fins de pesquisa. Respeite os termos de serviço de cada provedor e, se o dado for vinculado a CPF ou conta de investidor, trate-o como dado pessoal sob a LGPD.
A CaptchaAI resolve o Cloudflare Turnstile usado por provedores como Bloomberg?
Sim. O mesmo endpoint que resolve reCAPTCHA v2 resolve Turnstile — só muda o method enviado (turnstile) e o campo do token (cf-turnstile-response), como no exemplo acima.
Com que frequência posso consultar cotações sem disparar um novo CAPTCHA?
Para preços de ações, uma consulta por minuto durante o pregão costuma ser o teto seguro. Para arquivamentos, uma vez ao dia é o padrão do mercado. Passar disso tende a acionar CAPTCHA com mais frequência.
Faz diferença rodar os workers numa região específica da AWS?
Sim, para latência. Rodar os workers em sa-east-1 (São Paulo) reduz o RTT ao consultar Yahoo Finance e o SEC EDGAR a partir do Brasil, mas não muda a taxa de CAPTCHA em si — isso depende do volume de requisições, não da região.
Guias relacionados
- Como a qualidade do proxy afeta a taxa de resolução
- Rotação de proxies em coleta de dados
Mantenha a coleta de dados financeiros rodando sem travar em CAPTCHA — obtenha sua chave CaptchaAI e automatize a pesquisa de mercado.